 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Steering without Sacrifice: Principled Training of Steering Vectors for Prompt-only Interventions
May 07, 2026Recently, steering vectors (SVs) have emerged as an effective and lightweight approach to steer behaviors of large language models (LLMs), among which fine-tuned SVs are more effective than optimization-free ones. However, current approaches to fine-tuned SVs suffer from two limitations. First, they require careful selection of steering factors on a per-SV basis to balance steering effectiveness and generation quality at inference time. Second, they operate as full-sequence SVs (FSSVs), which can sacrifice generation quality regardless of factor selection due to excessive intervention on the model generation process. To address the first limitation, we propose joint training of steering factors and directions, such that post-hoc factor selection is no longer required. Using neural network scaling theory, we find that moderately large initialization sizes and learning rates for steering factors are essential for stability and efficiency of joint training. To tackle the second limitation, we draw inspiration from representation fine-tuning and introduce Prompt-only SV (PrOSV), an SV that intervenes only on a few prompt tokens. Our empirical results show that PrOSV outperforms traditional FSSVs on AxBench when using our joint training scheme. We also find that PrOSV achieves a better tradeoff between general model utility and adversarial robustness than FSSV.
PragLocker: Protecting Agent Intellectual Property in Untrusted Deployments via Non-Portable Prompts
May 07, 2026LLM agents rely on prompts to implement task-specific capabilities based on foundation LLMs, making agent prompts valuable intellectual property. However, in untrusted deployments, adversaries can copy and reuse these prompts with other proprietary LLMs, causing economic losses. To protect these prompts, we identify four key challenges: proactivity, runtime protection, usability, and non-portability that existing approaches fail to address. We present PragLocker, a prompt protection scheme that satisfies these requirements. PragLocker constructs function-preserving obfuscated prompts by anchoring semantics with code symbols and then using target-model feedback to inject noise, yielding prompts that only work on the target LLM. Experiments across multiple agent systems, datasets, and foundation LLMs show that PragLocker substantially reduces cross-LLM portability, maintains target performance, and remains robust against adaptive attackers.
Faithful Bi-Directional Model Steering via Distribution Matching and Distributed Interchange Interventions
Feb 05, 2026Intervention-based model steering offers a lightweight and interpretable alternative to prompting and fine-tuning. However, by adapting strong optimization objectives from fine-tuning, current methods are susceptible to overfitting and often underperform, sometimes generating unnatural outputs. We hypothesize that this is because effective steering requires the faithful identification of internal model mechanisms, not the enforcement of external preferences. To this end, we build on the principles of distributed alignment search (DAS), the standard for causal variable localization, to propose a new steering method: Concept DAS (CDAS). While we adopt the core mechanism of DAS, distributed interchange intervention (DII), we introduce a novel distribution matching objective tailored for the steering task by aligning intervened output distributions with counterfactual distributions. CDAS differs from prior work in two main ways: first, it learns interventions via weak-supervised distribution matching rather than probability maximization; second, it uses DIIs that naturally enable bi-directional steering and allow steering factors to be derived from data, reducing the effort required for hyperparameter tuning and resulting in more faithful and stable control. On AxBench, a large-scale model steering benchmark, we show that CDAS does not always outperform preference-optimization methods but may benefit more from increased model scale. In two safety-related case studies, overriding refusal behaviors of safety-aligned models and neutralizing a chain-of-thought backdoor, CDAS achieves systematic steering while maintaining general model utility. These results indicate that CDAS is complementary to preference-optimization approaches and conditionally constitutes a robust approach to intervention-based model steering. Our code is available at https://github.com/colored-dye/concept_das.
Scalable Multi-Stage Influence Function for Large Language Models via Eigenvalue-Corrected Kronecker-Factored Parameterization
May 08, 2025Pre-trained large language models (LLMs) are commonly fine-tuned to adapt to downstream tasks. Since the majority of knowledge is acquired during pre-training, attributing the predictions of fine-tuned LLMs to their pre-training data may provide valuable insights. Influence functions have been proposed as a means to explain model predictions based on training data. However, existing approaches fail to compute ``multi-stage'' influence and lack scalability to billion-scale LLMs. In this paper, we propose the multi-stage influence function to attribute the downstream predictions of fine-tuned LLMs to pre-training data under the full-parameter fine-tuning paradigm. To enhance the efficiency and practicality of our multi-stage influence function, we leverage Eigenvalue-corrected Kronecker-Factored (EK-FAC) parameterization for efficient approximation. Empirical results validate the superior scalability of EK-FAC approximation and the effectiveness of our multi-stage influence function. Additionally, case studies on a real-world LLM, dolly-v2-3b, demonstrate its interpretive power, with exemplars illustrating insights provided by multi-stage influence estimates. Our code is public at https://github.com/colored-dye/multi_stage_influence_function.
SongDriver: Real-time Music Accompaniment Generation without Logical Latency nor Exposure Bias
Sep 13, 2022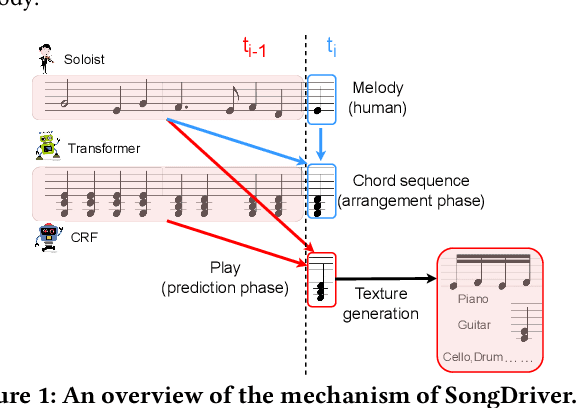
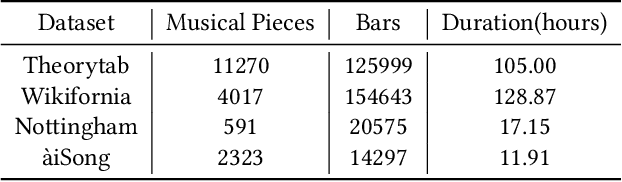
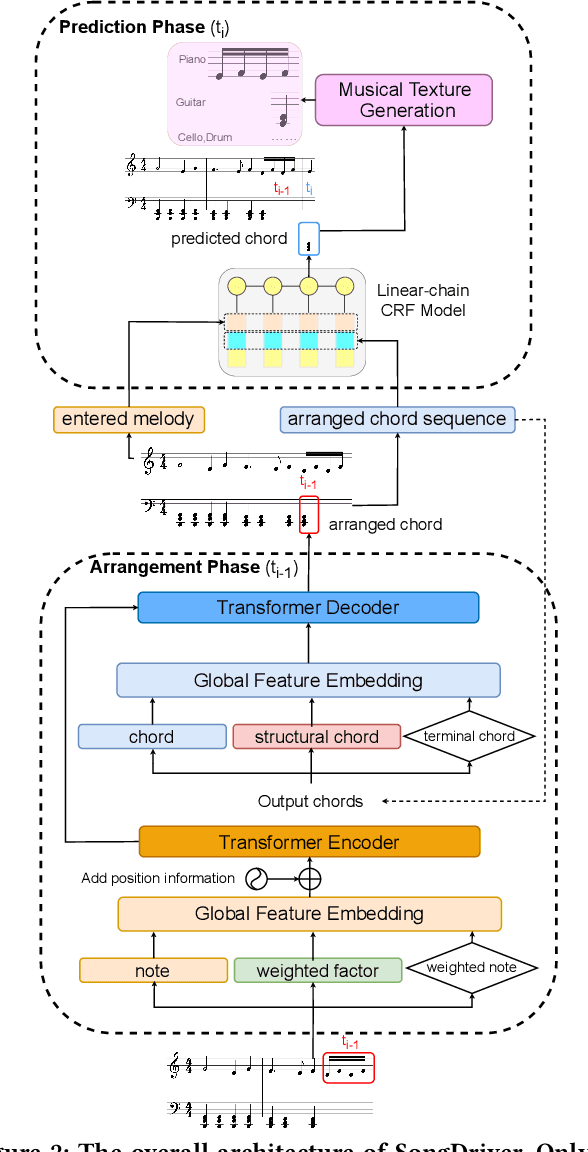
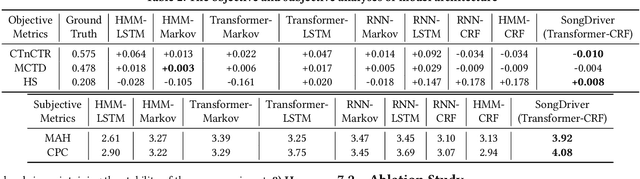
Real-time music accompaniment generation has a wide range of applications in the music industry, such as music education and live performances. However, automatic real-time music accompaniment generation is still understudied and often faces a trade-off between logical latency and exposure bias. In this paper, we propose SongDriver, a real-time music accompaniment generation system without logical latency nor exposure bias. Specifically, SongDriver divides one accompaniment generation task into two phases: 1) The arrangement phase, where a Transformer model first arranges chords for input melodies in real-time, and caches the chords for the next phase instead of playing them out. 2) The prediction phase, where a CRF model generates playable multi-track accompaniments for the coming melodies based on previously cached chords. With this two-phase strategy, SongDriver directly generates the accompaniment for the upcoming melody, achieving zero logical latency. Furthermore, when predicting chords for a timestep, SongDriver refers to the cached chords from the first phase rather than its previous predictions, which avoids the exposure bias problem. Since the input length is often constrained under real-time conditions, another potential problem is the loss of long-term sequential information. To make up for this disadvantage, we extract four musical features from a long-term music piece before the current time step as global information. In the experiment, we train SongDriver on some open-source datasets and an original \`aiSong Dataset built from Chinese-style modern pop music scores. The results show that SongDriver outperforms existing SOTA (state-of-the-art) models on both objective and subjective metrics, meanwhile significantly reducing the physical latency.